Sub zzz重複除外(ByRef zzh指定配列 As Variant)
Dim zz配列_Loop As Variant, zz作成配列() As Variant, zz配列要素数 As Long, zz判定辞書 As Object
If IsObject(zzh指定配列) = True Then
Err.Raise (13)
Exit Sub
Else: End If
Set zz判定辞書 = CreateObject("Scripting.Dictionary")
For Each zz配列_Loop In zzh指定配列
If zz判定辞書.Exists(zz配列_Loop) = False Then
zz判定辞書.Add zz配列_Loop, zz配列_Loop
ReDim Preserve zz作成配列(zz配列要素数)
zz作成配列(zz配列要素数) = zz配列_Loop
zz配列要素数 = zz配列要素数 + 1
Else: End If
Next zz配列_Loop
Erase zzh指定配列
zzh指定配列 = zz作成配列
End Sub
配列データに一括でデータを取得した後に、そのデータから重複データを削除してユニークなリストを作成する場合に使用する関数です
この関数はユニークではないデータを加工する関数なので、オブジェクト型では実行できません
オブジェクトはそれ自体がユニークな存在なのでそもそも意味がありません
関数の書式
引数(太字は必須引数)
(zzh指定配列)
「zzh指定配列」は、重複を除外したいリストの配列データです
配列データなのでValiant型になります
後述しますが、オブジェクトの代入自体は可能ですが関数内でエラーが発生します
コードの使用方法
Dim zz1次元 As Variant zz1次元 = Array(4, 1, 6, 3, 6, 7, 9, 7, 5, 4, 2, 2, 3, 7, 8, 8) Call zzz重複除外(zz1次元)
このコードでは配列の変数宣言を行い、その変数に1次元配列として適当に入力した数値を代入しています
所々、数値がかぶっているのが確認できると思います
その代入後に、その配列データを重複を除外するようにしたい場合に関数を使用します、SubプロシージャになりますのでCallステートメントを使用して引数に配列データを指定して実行してください
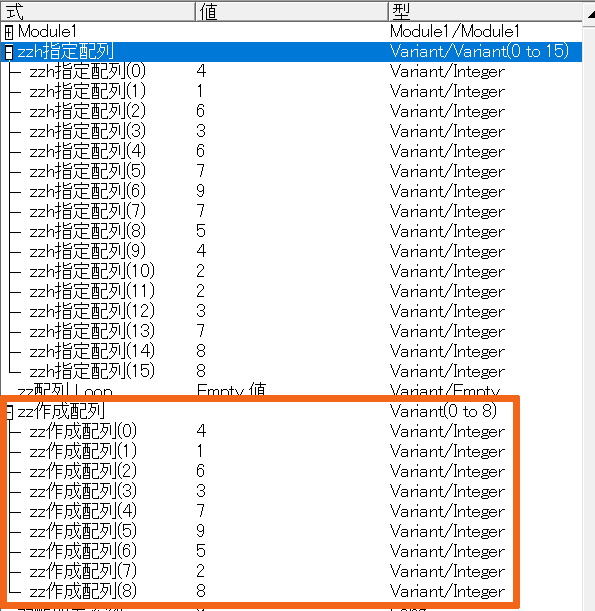
画像を確認してください
この画像の上側にある青くなっている行の部分からが最初に作成された配列データです
要素のいくつかがかぶっているものがあるのが確認できると思います
次に画像下部の赤枠内のデータが関数を使用して重複したデータを除外した配列データになります
同じ数値が要素内に存在していないことを確認してください
これが関数が完了後に引数に指定した配列がデータが振り替わります
例コードでいくと、「zz1次元」が赤枠内の配列データに振り替わる形になります
はい、確認して皆さんふと思いませんでしたかね
重複してないけど順番ぐちゃぐちゃやん、と
そんなあなたにお送りする記事が以下にあります、また見てね
コード解説
Sub zzz重複除外(ByRef zzh指定配列 As Variant) ~~ 中略 ~~ End Sub
ここの関数はSubプロシージャになります
この処理の目的として、元々ある配列データから重複しないリストを作成したい場合に使用します
つまり、元々の配列データがその後の処理に必要な前提がほぼありません
なので、この関数でその元配列を加工するほうが目的に即しています
なので、ここでは引数を1つ設定しています
「zzh指定配列」は配列データを代入されるのでValiant型です
また、この引数の配列を加工して戻すので配列変数自体を受け取る必要があるのでByRefキーワードを使用しています
これにより参照渡しとなり、この関数内で行った加工を呼び出し元に戻すことができます
Dim zz配列_Loop As Variant, zz作成配列() As Variant, zz配列要素数 As Long, zz判定辞書 As Object
プロシージャで使用する変数の宣言です
このプロシージャでは、3つの変数を使用します
「zz配列_Loop」は、Forループで引数の配列を1要素ずつ検証するための変数です
配列データを代入するのでValiant型です
「zz作成配列()」は、実際に作成する配列データです、重複している件数が初期時点で分からないため、動的配列でかつ都度要素数の再定義を行う必要があります
配列なのでValiant型です
「zz判定辞書」は、Dictionaryオブジェクトを代入する変数です
この重複検証にはいろいろ方法がありますが、DictionaryオブジェクトのExistsメソッドを使用するのが一番コードが分かり易いです
ここでもリストは作成していく形になりますが、あくまでも重複の検証判定用なのでデータとしては使用しません
実行時バインディングを行いますのでObject型です
If IsObject(zzh指定配列) = True Then
Err.Raise (13)
Exit Sub
Else: End If
ここでは引数に指定された配列データがObject型かどうかを判定しています
上記でも少し解説していますが、Object型はいわゆるRangeであったりするものです
これはそもそもがユニークな存在であり、重複しているものではありません
「Range(“A1”)」がワークシートの数だけ存在する、と思うかもしれませんが、実際の所、Excelからの指定が省略されているにすぎません
Addressプロパティが同じ、というだけに過ぎない訳です
なので、ユニークなリスト作成にそもそもオブジェクトは論外なのです
と、ごちゃごちゃ言いましたがこのIsObject関数がTrueを返せば、Object型になるので処理は行いません
その際実行時エラーを発生させています
それが「Err.Raise (13)」という箇所で、エラー13番を発生させるコードです
13番は型の不一致のエラーです、既存のものを使用しています
Set zz判定辞書 = CreateObject("Scripting.Dictionary")
ここはDictionaryオブジェクトのインスタンスの作成です
DictionaryオブジェクトはVBAの標準機能ではありません
そういったものを利用する際はこのようにインスタンスの作成を行う必要があります
このコードの動きを実行時バインディングといいます
このあたりは以下の記事で解説していますので確認してください
For Each zz配列_Loop In zzh指定配列
~~ 中略 ~~
Next zz配列_Loop
配列の1要素ずつのForループです
ここで指定された配列の全ての要素を検証しています
全ての要素を検証するので、次元数は問いません
2次元であったとしても全て1要素ずつ検証できるので、多次元配列を処理することは可能です
ですが、出力は1次元配列なのでそこに問題が無ければ、という前提にはなります
If zz判定辞書.Exists(zz配列_Loop) = False Then
~~ 中略 ~~
Else: End If
重複の検証を行う箇所です
DictionaryオブジェクトのExistsメソッドを使用することでデータがオブジェクトに存在するかを検証しています
ここで存在が無い(Falseが返される)なら、Dictionaryオブジェクトと作成する配列にデータを取得させることになります
存在がある(Trueか返される)なら、何もせず次の要素の検証を行います
zz判定辞書.Add zz配列_Loop, zz配列_Loop
まず、Dictionaryオブジェクトにデータの取得を行います
ここで取得を行うことで次に検証する材料を整えることが出来ます
ReDim Preserve zz作成配列(zz配列要素数)
zz作成配列(zz配列要素数) = zz配列_Loop
zz配列要素数 = zz配列要素数 + 1
ここで作成する配列への取得を行っています
作成する配列は要素数が未確定のため都度再定義する必要があります
「ReDim Preserve」を使用することによって動的配列の要素数の再定義を行っていますが、その際に元々取得済みのデータは保持されます
要素数の再定義が完了したら、その要素数にデータを代入させます
そして次の要素数の再定義を可能にするために、要素数変数の更新を行っています
Erase zzh指定配列
zzh指定配列 = zz作成配列
End Sub
最後に引数配列に作成した配列を代入します
その際、引数配列はEraseステートメントを使用して一旦初期化します
初期化したのち作成配列のデータをそのまま代入させます
これでこの関数が完了し、呼び出し元では引数に指定した配列データが加工済みになっている状態になります
最後にこの関数の使用上の注意点として、数値の「1」と文字列の「1」はそれぞれをユニーク値として判定します
これは解説したように、判定方法がDictionaryオブジェクトのExistsメソッドを使用していることに起因します
このメソッドがそういった仕様になっています
ですが、セルをそのまま取得したようなデータでない限り問題は無いはずです
それに配列の中でそういった型の違うデータを重複しているとするかしないかはその時の処理次第な場合が多いような気もします
結局、数値と文字列で重複を判定したとしてもどちらを取得するかは、その処理次第ということです